Big Data and Time: What’s the Connection?

I know that may sound silly, but really, “big” is actually even an understatement. And that’s the difficult part to grasp when trying to understand Big Data: The volume of data is so large that it’s beyond the scale of things we’re used to seeing or working with every day, and it is almost impossible to imagine. So, before we get into how precision time fits within Big Data, let’s add some context. Specifically, let’s try to get a better sense of the scale of Big Data.
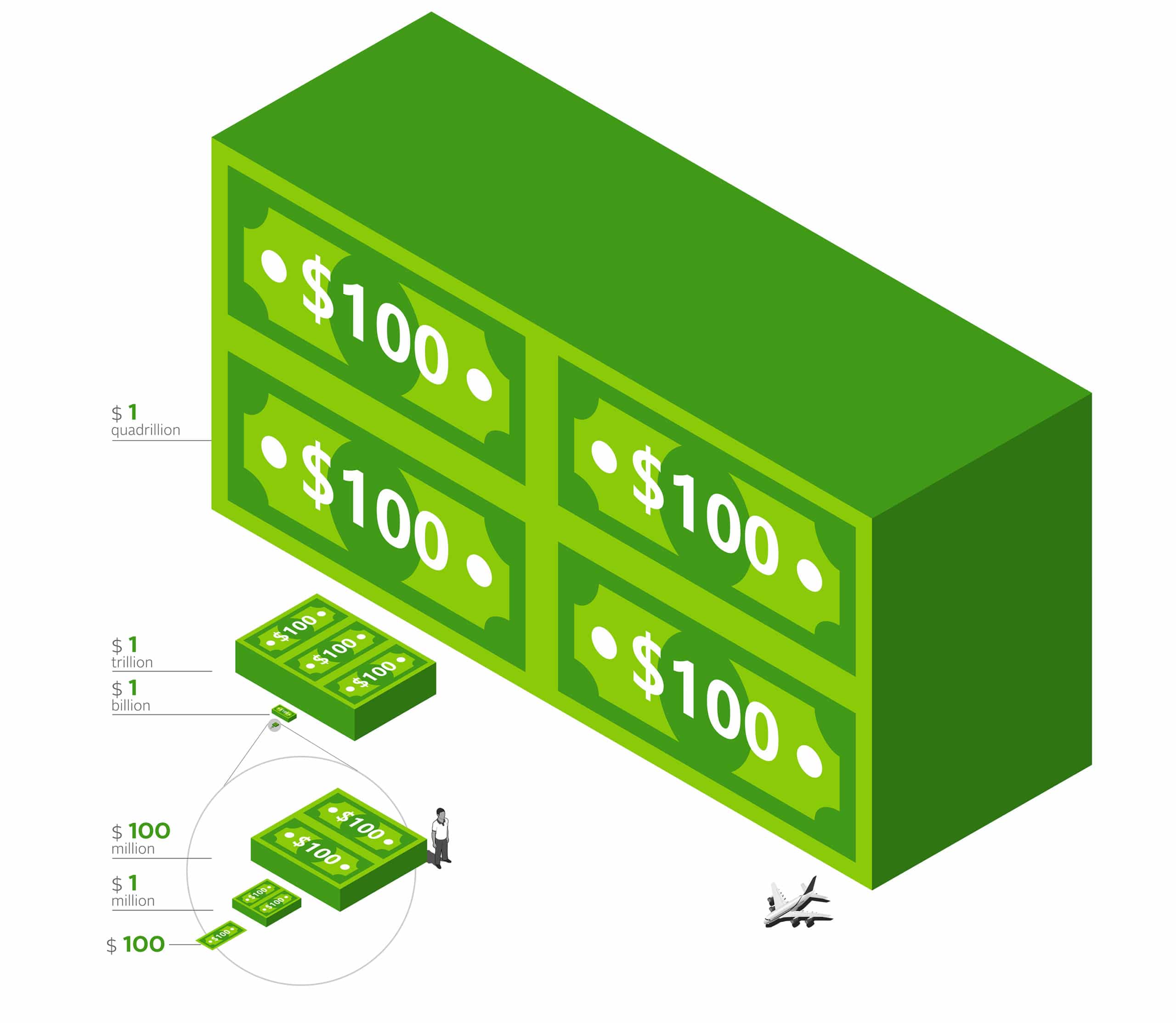
To do that, we are going to use money. When you think about data, let alone Big Data, what do you picture? Maybe you picture a datacenter, a server, some lines of code on a terminal … different people will picture different things because data is relatively intangible. You can’t touch it or feel it. But we’re all familiar with the general size, shape, and feel of money so let’s use that as a proxy for data in understanding the scale of Big Data.

We’ll start with a one hundred dollar bill.
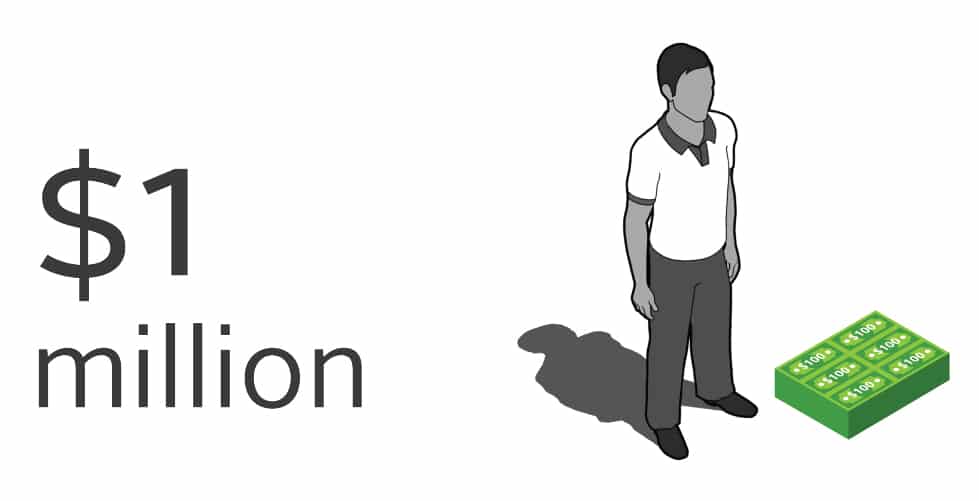
Next, this is what $1M would look like using $100 bills. I know what you’re thinking – it doesn’t look like much.

But if we add a few zeros to that number and turn it into $1B, suddently it starts to become a much more respectable pile of money. You go from something you could easily carry by hand to something you’d need a moving truck for. But at least you could afford a really good moving truck if you had all of that money. The point, though, is as we increase the order of magnitude, the scale that it relates to grows tremendously. And if you don’t believe me, let’s take a look at $1 trillion.

This is what $1T looks like. In our minds, when we think about the difference between one billion and one trillion, it’s typically in the form of a math equation. We don’t tend to think about what it actually looks like. And this is compounded even more when we talk about Big Data, which is just packets of information moving around a network that doesn’t have a physical appearance to begin with. Even though $100 bills are tangible, physical things, did you know that this is what $1T looks like? We all know what money looks like; we all know its size and physical properties, yet despite that, it’s surprising to see what $1T looks like because we don’t tend to have the right perspective of scale to reference against.
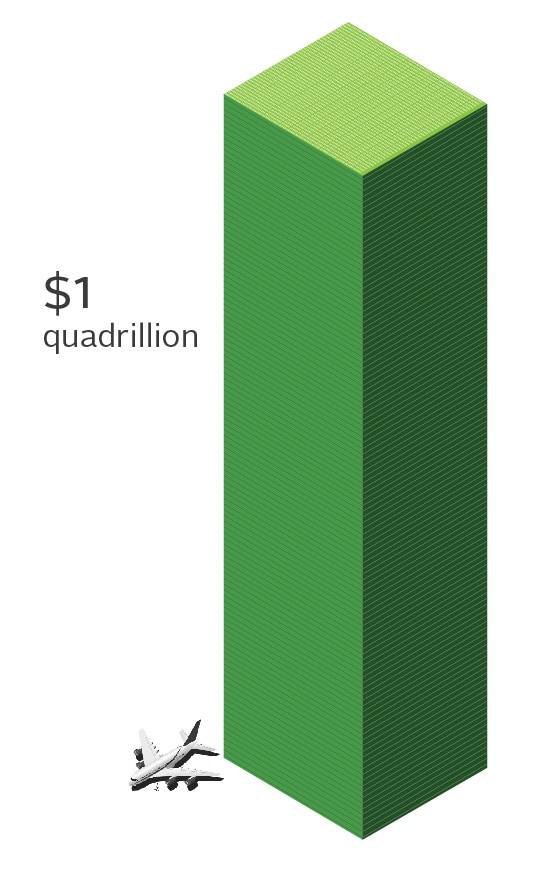
But since we’re at it, let’s keep going with the analogy and look at something closer to the scale we’re dealing with in Big Data: $1Q.
The point of all of this is to try to understand and appreciate the scale of data we’re dealing with when we talk about Big Data. It’s very difficult to do. But at the same time, it’s very important to understand because that scale is why precision time is so important to Big Data infrastructures.
There are many, many things we take for granted that rely upon these Big Data systems. Everything just works, and we don’t think much about it. However, there is a huge amount of effort and infrastructure that exists to operate and support it. But the pace of the growth of Big Data is accelerating. Big Data is getting even bigger, even faster. And that’s a problem.
Traditionally, the primary solution has been to throw hardware at the problem. The programs that manage Big Data are designed to use massively parallel and distributed systems. So basically, in order to add capacity, you just add more hardware – servers, switches, routers, etc. – and the problem is solved.
But we’re reaching a point where it’s becoming less and less efficient to just throw hardware at the problem. It turns out that continuously adding hardware doesn’t scale linearly. You start to create new issues, not to mention the physical requirements, ranging from datacenter floor space to power, heating, and cooling, etc.
Right now, there is a big push across the industry to rethink things and find new methods capable of supporting the increasing growth. A lot of that focus has been on improving efficiency. And that’s where precision time comes in. First, precision time is needed for network performance monitoring. Simply put, how can you accurately measure the flow of traffic across your network if the time you’re basing those measurements on is not accurate to begin with? Or you can only loosely correlate events between disparate sites?
Network performance monitoring is key to improving efficiencies in Big Data and in order to do that well, you need good synchronization across all of the network elements so that you can see exactly where and when bottlenecks occur.
The second use of precision time for Big Data is a little bit more abstract still. It’s a new methodology centered around making distributed systems more efficient by making decisions based on time. I won’t bore you with the technical details. Instead, I’ll just bore you with the basic concept. And that basic concept is using time to make decisions.
Whenever you do something in the cloud, data is always stored on more than one server and in more than one physical location. Because of this, that same data can arrive at those different servers at different times. What this means is that sometimes, when an application goes to call that a piece of data, it can get different results from different servers. These are called data conflicts and they are especially common in eventually consistent databases.
When data conflicts occur, the application has to stop and talk to the servers to figure out which one is right. That is, which server has the most recent version of data which is what the application needs. This all happens very quickly, but it uses processing power and it uses network bandwidth and it takes time. The new methodology of making decisions based on time would look at the timestamps on the data instead and be able to easily make a decision based on those timestamps.
Now I know that may seem trivial. After all, how much time and processing power and bandwidth is that really saving? However, you can’t lose sight of the scale we’re talking about with Big Data. You need to remember the scale of data that Big Data operators are trying to manage – both in terms of the sheer volume of data and the rate at which that data is changing or updating – because at such scale, even those small numbers can accumulate to large sums.
So if precision time can make a big difference for Big Data, then why aren’t all of the Big Data operators using it in their networks? Well, to be clear, some are. But for more detail on that question, stay tuned. We’ll dive into that next time.